논문 요약
기존의 optical flow이나 particle video tracking 알고리즘은 제한된 temporal windows 내에서만 작동하여 occlusions를 추적하고 움직임 궤적(motion trajectories)의 전체적인 일관성을 유지하는 데 어려움이 있다. 제안하는 OmniMotion은 비디오를 quasi-3D canonical volume으로 나타내고, 로컬과 글로벌 공간 간의 일대일 대응(bijections)을 사용하여 모든 픽셀의 움직임을 추적합니다. 이를 통해 전체 비디오에 걸쳐 정확한 움직임 추정이 가능해지며, occlusions를 추적하며 카메라 및 객체의 모든 움직임 조합을 모델링할 수 있다. TAP-Vid 벤치마크와 real world 영상에 대한 평가 결과, OmniMotion은 기존 방법들보다 크게 우수한 성능을 보였다.
추가설명: Quasi-3D representation
완전한 3차원 표현은 아니지만, 3차원 공간의 일부 특성을 모사하여, 보다 낮은 차원에서 3차원 데이터를 다루거나 표현하는 방식. OmniMotion은 비디오의 모든 프레임을 작은 3차원 공간으로 생각한다. 각 프레임의 이 공간들은 표준화된 3차원 모델에 대응되어 연결된다. 이런 방식으로 각 프레임 사이의 움직임을 매끄럽게 추적할 수 있으며, 이는 모든 프레임을 통틀어 객체가 어떻게 움직이는지 전체적으로 이해할 수 있도록 도와준다. 그 결과, occlusion과 같은 문제가 발생해도 객체의 움직임을 잃어버리지 않고 추적할 수 있다.
1. Paper Bibliography
@inproceedings{wang2023omnimotion,
title = {Tracking Everything Everywhere All at Once},
author = {Wang, Qianqian and Chang, Yen-Yu and Cai, Ruojin and Li, Zhengqi and Hariharan, Bharath and Holynski, Aleksander and Snavely, Noah},
booktitle = {International Conference on Computer Vision},
year = {2023}
}
2. Problems & Motivations
기존의 움직임 추적(motion estimation)은 크게 두가지 방법으로 접근하였다: sparse feature tracking과 dense optical flow. 그러나 기존의 방법들은 제한된 범위에서는 유용하게 작용하였으나, 전체 비디오의 모든 픽셀을 추적하는데 작동하는 temporal windows에 제한이 있었고 전역적 일관성(global consistency) 유지에 어려움을 겪었습니다. 특히, optical flow는 짧은 시간에 걸친 움직임만을 포착하는 데 국한되고, sparse tracking은 비디오 내 전체 픽셀에 대한 움직임을 모델링하지 못했다.
3. Method
본 논문은 비디오 시퀀스에서 움직임을 밀도 있고 장기간에 걸쳐 추정하는 새로운 최적화 방법을 제안한다. 이 방법은 비디오의 각 프레임과 그 사이의 움직임을 추정하는 optical flow와 같은 데이터를 사용하여 비디오 전체에 대해 complete, globally consistent한 motion representation을 만든다. 이 representation은 최적화되어 어떤 프레임에서든 쿼리 픽셀을 통해 전체 비디오에 걸쳐 부드러운 움직임의 경로를 생성할 수 있다. 이 방법은 물체의 occlusion도 인식하고 가려진 포인트의 움직임을 추적할 수 있다.
4. OmniMotion representation
전통적인 움직임 표현 방식들, 예를 들어 이미지 쌍 사이의 광학 흐름(optical flow)은 물체가 가려지는 상황에서 움직임을 정확하게 추적하는 데 한계가 있으며, 여러 프레임에 걸쳐 결과를 제공할 때 일관성이 결여될 수 있다. 가려짐(occlusion)이 발생하더라도 정확하고 일관된 움직임 추적을 실현하기 위해서는 보다 포괄적인 움직임 표현 방식, 즉 전역적인 움직임 표현(global motion representation)이 필수적이다. 이러한 전역적 표현 방법 중 하나는 장면을 별도의 깊이로 구분된 여러 레이어로 나누는 것이다. 하지만 대부분의 실제 세계 상황에서는 고정되고 정렬된 레이어 집합으로 장면을 나타내는 것이 어렵다. 또 다른 접근법은 카메라의 위치, 3D 기하학적 구조 등을 포함한 완전한 3D 재구성이지만, 이는 매우 복잡한 문제이다. 이에 대해 저자들은 명시적인 동적 3D 재구성 없이 실제 세계의 움직임을 추정할 수 있는 방법이 있을지에 대한 질문을 제기한다.

저자들은 이를 제안하는 'OmniMotion'을 통해 질문을 답한다. OmniMotion은 비디오 장면을 canonical 3D volume으로 나타내고, 각 프레임을 local-canonical bijections를 통해 local volumes에 매핑하는 방식이다. 이 때 local-canonical bijections는 신경망을 통해 파라미터화 되며 카메라와 장면의 움직임을 둘 다 포착하지만, 둘을 분리하지는 않는다. 그 결과, 비디오는 고정된, 정적인 카메라에서 생성된 local volumes의 렌더링으로 간주될 수 있다.
OmniMotion은 카메라와 장면의 움직임을 명시적으로 분리하지 않기 때문에, 물리적으로 정확한 3D 장면 재구성이 아니다. 대신, 이를 '유사-3D 표현(quasi-3D representation)'이라고 부르며, 이는 3D reconstruction을 어렵게 만드는 모호성들을 피할 수 있게 해준다. 이런 접근 방식은 가려짐이 발생하더라도 일관되고 정확한 장기간 추적에 필요한 속성을 유지할 수 있다.
1) OmniMotion은 local frame과 canonical frame 사이에 일대일 대응(bijection) 관계를 설정함으로써 모든 로컬 프레임에 걸쳐 전역적으로 일관된 3D 매핑을 보장한다. 이는 실제 세계의 3D 참조 프레임 사이의 일대일 대응을 모방한다.
2) OmniMotion은 모든 장면 점들에 대한 정보를 유지합니다. 이 점들은 각 픽셀에 투영되며, 그들의 상대적 깊이 순서와 함께, 물체가 가려질 때도 움직임을 추적할 수 있게 해준다.
4.1. Canonical 3D volume
비디오 장면은 3차원의 canonical volume G를 통해 표현된다. 여기서 각 canonical 3D 좌표 u∈G를 밀도 σ 와 색 c로 매핑하는 좌표 기반 네트워크 F_θ를 정의된다. G에 저장된 밀도는 canonical 공간 내의 표면 위치를 알려주는 중요한 정보를 제공한다. 이 정보는 여러 프레임에 겇려 표면을 추적하고 occlusion을 추론하는 데 사용된다. 또 G에 저장된 색상은 최적화과정에서 photometric loss를 계산하는 데에 활용된다.
4.2. 3D bijections
T_i는 local coordinate frame L_i의 3D 포인트 x_i를 canonical 3D coordinate frame u = T_i(x_i)로 매핑하는 연속적인 bijection mapping이다. 이는 시간에 독립적이며, 장면이나 시간에 따른 3D 궤적에 대한 전역적으로 연속적인 '인덱스'로 기능한다. 이러한 일대일 대응 함수를 통해, 하나의 프레임에서 다른 프레임으로 3D 포인트를 매핑할 수 있으며, 이러한 일대일 대응 함수와 그 역함수를 결합해 local 3D coordinate 의 3D 포인트를 프레임 (L_i)에서 (L_j)로 매핑할 수 있다.
이 과정은 Real-NVP를 사용한 가역 신경망(INNs)을 통해 파라미터화됩니다. 각 프레임에 대한 매핑은 고유한 latent code ψ_i를 포함하여, 매핑이 각 프레임의 독특한 특성을 반영하도록 한다. 모든 invertible 매핑 T_i는 동일한 invertible 네트워크 M_θ로 파라미터화되지만 다른 latent code를 사용한다: T_i(\cdot) = M_{\theta}(\cdot; \psi_i)
4.3. Computing frame-to-frame motion
프레임 간의 움직임을 계산하는 과정은 프레임 i에서 픽셀 p_idml 3D 공간으로의 'lift', 다른 프레임 j로의 매핑, '렌더링'을 통한 최종적인 2D 대응점 계산을 포함한다. 이는 고정된 정사영 카메라 모델을 사용한다고 가정하며, 각 픽셀 위치에서 광선을 따라 여러 깊이 값을 샘플링해, 다양한 표면이 픽셀에 어떻게 투영되는지 파악한다. 이후, 샘플링한 점들의 밀도와 색상을 F_θ를 쿼리하여 얻어 최종적으로 2D 대응점을 계산한다.
- \hat{x}_j: 합성된 3D 위치
- x^k_j: j번째 프레임에서 k번째 샘플 위치
- a_k: k번째 샘플의 밀도를 기반으로 계산된 투명도를 나타내는 알파 값
- T_k: k-1번째 샘플까지의 누적 가시성. 이전 샘플들의 알파 값을 곱하여 구한다. 이는 현재 샘플 앞에 있는 모든 샘플들이 얼마나 많은 빛을 차단하는지를 고려한다.
정리:
1. Canonical 3D Volume 생성: 비디오 장면을 3D 공간 내의 볼륨, 즉 Canonical Volume G로 변환한다. 이 볼륨은 각 좌표가 특정 밀도(σ)와 색상(c)을 가지며, 이를 통해 장면의 3D 구조와 모양을 표현한다.
2. 3D Bijections 정의: 각 비디오 프레임의 3D 포인트를 Canonical Volume 내의 3D 좌표로 매핑하는 일대일 대응(bijection) 함수 T_i를 정의한다. 이 함수들은 신경망을 통해 파라미터화되며, 장면의 움직임을 전역적으로 일관된 방식으로 추적하는 데 사용됩니다.
3. 프레임 간 움직임 계산: 주어진 픽셀의 위치에서 시작하여, 해당 픽셀을 3D 공간으로 "올린" 후("lift"), 해당 3D 포인트를 다른 프레임의 3D 공간으로 매핑한다. 이 과정을 통해, 한 프레임에서 다른 프레임으로의 움직임을 추적할 수 있다.
4. 2D 대응점 계산: 매핑된 3D 포인트들을 다시 2D 픽셀 위치로 "투영"하여, 원래 프레임과 타겟 프레임 간의 움직임을 2D 공간에서 나타낸다.
5. 움직임 추적 및 렌더링: 계산된 2D 대응점을 기반으로 비디오 내 객체의 움직임을 추적한다. 이 과정에서는 가려짐과 같은 복잡한 상황도 고려되어, 보다 정확하고 일관된 움직임 추적이 가능해진다.
5. Optimization
최적화 과정은 비디오 시퀀스와, 기존 방법에서 얻은 노이즈가 있는 대응 집합들을 입력으로 받아 전체 비디오에 대한 일관된 모션 정보를 만드는 것을 목표로 한다.
5.1. Collecting input motion data
실험 대부분에서, RAFT를 사용하여 입력된 pairwise correspondence를 계산한다. 우리는 또한 TAP-Net과 같은 다른 밀집 대응 방법을 실험해 보고, 우리의 접근법이 다양한 타입에 대해서 일관되게 잘 작동함을 입증한다.
5.2. Loss functions
기본 손실 함수는 flow loss. 예측한 optical flow와 gt flow 비교.
예측된 색상과 원본 비디오 프레임 색상 사이의 차이도 photometric loss로 최소화한다
마지막으로 temporal smoothness를 보장하기 위해 큰 가속도에 패널티를 주는 정규화 항을 적용한다
최종 Loss는 다음과 같다.
5.3. Balancing supervision via hard mining
네트워크가 배경의 단순한 움직임에만 집중하고 복잡한 전경의 움직임을 놓치는 것을 방지하기 위해 훈련 중 어려운 예제를 집중적으로 학습하는 전략을 사용하여 오류가 더 많이 발생하는 영역을 더 자주 샘플링하도록 한다.
4. Experiments
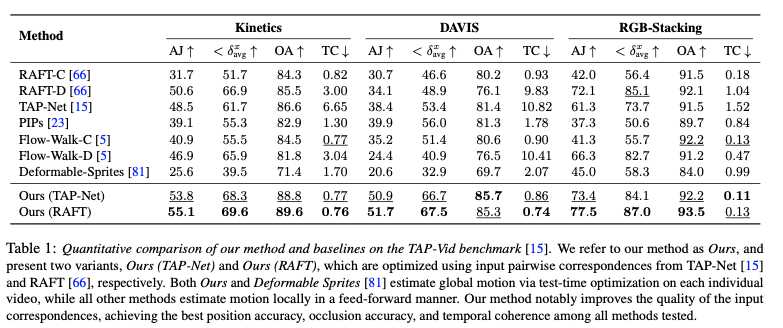
긴 비디오 클립에서 point tracking의 성능을 평가하도록 설계된 TAP-Vid 벤치마크에서 평가

Paper Link
https://arxiv.org/abs/2306.05422
Tracking Everything Everywhere All at Once
We present a new test-time optimization method for estimating dense and long-range motion from a video sequence. Prior optical flow or particle video tracking algorithms typically operate within limited temporal windows, struggling to track through occlusi
arxiv.org
Google Scholar Link
Google 학술 검색
We present a new test-time optimization method for estimating dense and long-range motion from a video sequence. Prior optical flow or particle video tracking algorithms typically operate within limited temporal windows, struggling to track through occlusi
scholar.google.co.kr
GitHub
https://github.com/qianqianwang68/omnimotion?tab=readme-ov-file
GitHub - qianqianwang68/omnimotion
Contribute to qianqianwang68/omnimotion development by creating an account on GitHub.
github.com
댓글