Paper Info
- ECCV 2024
- Tianqi Liu, Guangcong Wang, Shoukang Hu, Liao Shen, Xinyi Ye, Yuhang Zang, Zhiguo Cao, Wei Li, Ziwei LiuJiahui Zhang, Fangneng Zhan, Muyu Xu, Shijian Lu, Eric Xing
- Huazhong University of Science and Technology | S-Lab, Nanyang Technological University | Great Bay University | Shanghai AI Laboratory
Introduction
Novel View Synthesis(NVS)은 여러 시점에서 촬영된 소스 이미지를 바탕으로 새로운 시점의 이미지를 합성하는 기술이다. 대표적으로 NeRF가 implicit radiance field을 활용해 큰 성공을 거두었지만, 높은 계산 비용과 긴 렌더링 시간이 단점으로 지적되었다. 최근 3D Gaussian Splatting(3D-GS)은 장면을 이방성(anisotropic) 가우시안들의 집합으로 명시적으로 표현하여 NeRF 대비 빠른 렌더링을 구현했다. 그러나 기존 방식은 장면별 최적화가 필요하고, 그 과정에서 여전히 시간과 연산 비용이 많이 든다. 따라서 다수의 새로운 장면에 대해 장면별 파인튜닝(fine-tuning) 없이도 합리적인 품질의 시각화를 제공할 수 있는 ‘범용(generalizable) 모델’의 필요성이 제기된다.
본 논문에서는 Multi-View Stereo(MVS)를 활용해 깊이(depth)를 추정하고, 픽셀 정렬(pixel-aligned) 방식의 3D 가우시안 표현을 구축한다. 이렇게 인코딩된 점 단위(point-wise) 특징을 MLP로 디코딩하여 가우시안 파라미터를 얻으며, 깊이 기반 볼륨 렌더링을 추가하여 모델의 일반화 성능을 한층 높였다. 학습이 끝난 범용 모델은 여러 시점에서 3D 가우시안을 생성할 수 있는데, 이를 곧바로 장면별(per-scene) 후속 최적화의 초기값으로 사용할 경우, 최적화 도중 가우시안이 과도하게 분열·복제되어 불필요한 계산 비용이 증가할 수 있다. 이에 본 논문에서는 다중 시점 간 기하학적 일관성(geometric consistency)을 유지하도록 가우시안을 집약(aggregate)하여, 핵심 점만 보존하는 방식을 제안한다. 이를 통해 장면별 최적화를 빠르게 수행할 수 있도록 고품질 초기값을 제공한다.
Method

여러 개의 소스 뷰가 주어졌을 때, 새로운 카메라 포즈(camera pose)에서 타겟 뷰를 합성(Novel View Synthesis, NVS)하는 것을 목적으로 한다.
- 멀티스케일 특징 추출
먼저 Feature Pyramid Network(FPN)을 활용해 소스 뷰로부터 다양한 스케일의 특징 맵을 추출한다. 이렇게 얻은 멀티스케일 특징들은 이후 깊이 추정 과정에서 정교한 정보를 제공한다. - 비용 볼륨 생성 및 깊이 추정
다음으로, 미분 가능한 호모그래피(differentiable homography)를 사용해 추출된 특징들을 목표 카메라 뷰(프러스텀)로 투영하고, 이를 통해 비용 볼륨(cost volume)을 생성한다. 그런 뒤 3D CNN을 적용해 정규화(regularization) 과정을 거치고, 최종적으로 깊이 맵(depth map)을 산출한다. - 픽셀 정렬 3D 포인트 특징 인코딩
산출된 깊이 맵을 바탕으로 이미지를 3D 공간으로 역투영(unprojection)해, 각 픽셀에 해당하는 3D 포인트를 만든다. 이후 멀티뷰 특징과 공간 정보를 합쳐, 픽셀 정렬(pixel-aligned) 3D 포인트에 대한 특징을 인코딩한다. 이 인코딩된 특징을 디코딩하면, **가우시안 스플래팅(Gaussian Splatting)**에 필요한 파라미터들을 얻을 수 있다. - 하이브리드 가우시안 렌더링
가우시안 스플래팅은 3D 공간의 가우시안을 2D 픽셀로 매핑하는 과정에서 다대다(many-to-many) 관계를 형성해 학습 난이도가 높아진다. 이를 보완하고자, 깊이 정보 기반 볼륨 렌더링(depth-aware volume rendering) 모듈을 추가한다. 여기서는 광선(ray)마다 오직 하나의 샘플만 취하는 단순화된 방식을 사용한다. 이후 가우시안 스플래팅으로 얻은 뷰와 볼륨 렌더링으로 얻은 뷰를 각각 생성하고, 두 결과를 평균 내 최종 합성 영상을 만든다. - 계단식(cascade) 구조
전체 과정을 coarse에서 fine으로 이어지는 계단식(cascade) 구조로 반복 수행한다. 초기 단계에서 대략적인 깊이 맵과 렌더링 결과를 얻고, 이를 점차 세밀하게 보정해 나가면서 높은 수준의 정교함을 달성한다.
4.2 MVS-based Gaussian Splatting Representation
Depth Estimation from MVS
여러 소스 뷰를 타겟 뷰에 미분 가능한 호모그래피 방식으로 투영하여 비용 볼륨(cost volume)을 구성하고, 3D CNN 정규화를 거쳐 최종 깊이 맵(depth map)을 추론한다.

- $K_i$, $R_i$, $t_i$ : 소스 뷰 I_i 의 카메라 파라미터 (내부행렬, 회전행렬, 평행이동)
- $K_t$, $R_t$, $t_t$ : 타겟 뷰의 카메라 파라미터
- $a$ : 타겟 뷰의 광선(principal axis)
- $z$ : 샘플링된 깊이(depth)
Pixel-aligned Gaussian Representation
추정된 깊이 맵을 바탕으로, 각 픽셀 좌표를 3D 공간으로 역투영(unproject)하여 가우시안 위치를 구하고, 멀티뷰 특징을 통합하여 가우시안 파라미터(스케일, 회전, 색상 등)를 디코딩한다.

- $mu$ : 가우시안의 3D 위치
- $Pi^-1$ : 역투영(unprojection) 연산
- $(x, d)$ : 2D 픽셀 좌표 (x, y)와 깊이 d
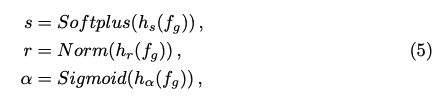
- $s$ : 스케일(scale) 벡터
- $r$ : 회전을 나타내는 쿼터니언(quaternion)
- $alpha$ : 가우시안의 불투명도(혹은 투명도)
- $f_g$ : 픽셀 정렬 후 인코딩된 특징 (멀티뷰 + U-Net 등)
- $h_s$, $h_r$, $h_alpha$ : MLP 헤드 (각 속성 예측)

- $c$ : 가우시안의 색상(RGB)
- $h_c$ : 색상 예측용 MLP 헤드
Efficient Hybrid Gaussian Rendering
가우시안 스플래팅과 깊이 기반 볼륨 렌더링을 결합(하이브리드)하여, many-to-many 매핑 문제를 완화하고 보다 효율적인 뷰 합성을 구현한다. 계단식(cascade) 구조로 coarse단계에서 fine단계로 점진적으로 품질을 개선한다.
4.3 Consistent Aggregation for Per-Scene Optimization

Depth Estimation from MVS
범용 모델(generalizable model)을 통해 여러 시점에서 가우시안 포인트 클라우드를 추론할 수는 있지만, 이를 단순히 합치면 잡음이 늘어나고 점 개수가 과도해져 최적화와 렌더링 속도가 저하된다. 또한 단순 다운샘플링을 적용하면 유효한 점까지 제거되어 성능 손실이 우려된다. 이를 해결하기 위해 멀티뷰 기하학적 일관성(multi-view geometric consistency)을 활용해 잡음이 많은 점만 선별적으로 제거하고, 의미 있는 점들은 최대한 보존한다. 더불어 뷰 간 재투영(reprojection)을 통해 픽셀 단위의 일관성을 검사하고, 일정 오차 이하일 때만 해당 점을 신뢰할 수 있는 깊이(3D 점)로 인정한다.

- $p$ : 기준 뷰(reference view)에서의 픽셀 좌표
- $D_0$ : 기준 뷰의 깊이 맵
- $Pi_{0->1}$ : 뷰 0에서 뷰 1로 변환(프로젝션) 연산
- $d$ : 투영 과정에서의 깊이 값
- $q$ : 인접 뷰(뷰 1) 상의 픽셀 좌표

- $q$ : 인접 뷰(뷰 1)에서의 픽셀 좌표
- $D_1$ : 뷰 1의 깊이 맵
- $Pi_{1->0}$ : 뷰 1에서 뷰 0으로 변환(프로젝션) 연산
- $d'$ : 재투영 과정에서의 깊이 값
- $p'$ : 재투영된 픽셀 좌표 (다시 기준 뷰 상에서)

- $xi_p$ : 재투영 픽셀 오차 (p와 p'의 차이)
- $xi_d$ : 깊이 상대 오차
- $D_0(p)$ : 기준 뷰에서 픽셀 p의 깊이
- $d'$ : 재투영 시 추정된 깊이

- $theta_p(n)$, $theta_d(n)$ : 뷰의 개수 n에 따라 달라지는 임계값(Threshold)
- $xi_p, xi_d$ : 식 (9)에서 정의된 오차
- n개 이상의 뷰에서 임계값을 만족하면 해당 점은 신뢰 가능하다고 판단
위 과정을 통해, 장면별(per-scene) 최적화 시 잡음이 많은 점들을 효율적으로 제거하고, 적은 수의 고품질 가우시안 포인트 클라우드를 확보할 수 있다. 이는 최적화 및 렌더링 속도를 높이고, 최종 뷰 합성 품질에도 긍정적인 영향을 준다.
4.4 Full Objective
범용 모델(generalizable model) 학습
RGB 이미지를 통한 엔드투엔드(end-to-end) 학습을 수행하며, 평균 제곱 오차(MSE), SSIM 손실, 퍼셉추얼 손실(perceptual loss)을 이용해 최적화한다. 단, 다단계(cascade) 구조를 갖추었기 때문에, 각 단계별 손실을 가중합(aggregate)하여 최종 손실로 사용한다.
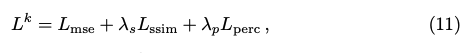
- $L^k$ : k번째 단계에서의 총 손실
- $L_mse$ : 평균 제곱 오차(MSE) 손실
- $L_ssim$ : SSIM 기반 손실
- $L_perc$ : 퍼셉추얼(perceptual) 손실
- $lambda_s$, $lambda_p$ : 각 손실 항에 대한 가중치

- $L$ : 전체 손실
- $L^k$ : k번째 단계에서의 손실 (식 11)
- $lambda^k$ : k번째 단계에 대한 손실 가중치
장면별(per-scene) 최적화
손실과 D-SSIM 항을 결합한 형태로, 초기에 범용 모델이 생성한 가우시안 포인트 클라우드를 빠르게 fine-tune한다.

- $L_ft$ : 장면별 최적화를 위한 최종 손실
- $L_1$ : L1 손실 항
- $L_{D-SSIM}$ : D-SSIM 손실 항
- $lambda_ft$ : 해당 손실 항의 가중치
이로써, 깊이 맵 추정 + 가우시안 스플래팅 파라미터 학습 + 하이브리드 렌더링을 총체적으로 학습하고, 필요에 따라 장면별 최적화를 수행하여 뷰 합성 품질을 극대화할 수 있음.
Experiments
5.1 Settings
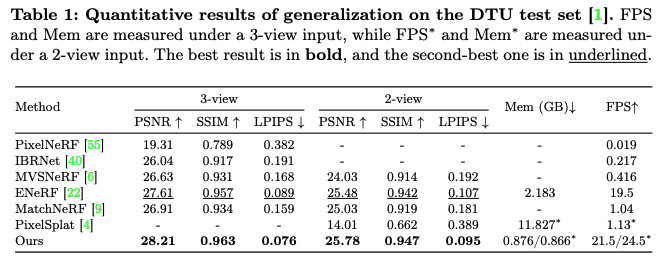
Datasets: DTU [1] 학습 세트로 모델을 학습하고, DTU 테스트 세트 및 Real Forward-facing, NeRF Synthetic, Tanks and Temples에서 추가 실험을 수행.
Implementation Details: Adam 옵티마이저 사용, 장면별 최적화는 3D-GS 설정에 맞춰 공정 비교.
5.2 Generalization Results
DTU, Real Forward-facing, NeRF Synthetic, Tanks and Temples 데이터셋을 대상으로 테스트.


5.3 Per-Scene Optimization Results
장면별 최적화 수행 시, 범용 모델이 제공하는 초기화(initialization)가 정확도와 최적화·렌더링 속도 모두에 이점을 제공.

단 45초의 최적화만으로 3D-GS와 동등 혹은 그 이상의 성능을 달성할 수 있으며, NeRF 대비 압도적으로 빠름(NeRF는 몇 시간 소요)

5.4 Ablations and Analysis



Paper Link
https://arxiv.org/abs/2405.12218
MVSGaussian: Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
We present MVSGaussian, a new generalizable 3D Gaussian representation approach derived from Multi-View Stereo (MVS) that can efficiently reconstruct unseen scenes. Specifically, 1) we leverage MVS to encode geometry-aware Gaussian representations and deco
arxiv.org
Google Scholar Link
https://scholar.google.co.kr/scholar?hl=ko&as_sdt=0%2C5&q=MVSGaussian&btnG=
Google 학술 검색
J Hu, Z Chen, Z Li, Y Xu, J Zhang - arXiv preprint arXiv:2412.02245, 2024 - arxiv.org Recently, several studies have combined Gaussian Splatting to obtain scene representations with language embeddings for open-vocabulary 3D scene understanding. While the
scholar.google.co.kr
GitHub
https://github.com/TQTQliu/MVSGaussian
GitHub - TQTQliu/MVSGaussian: [ECCV 2024] MVSGaussian: Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Ster
[ECCV 2024] MVSGaussian: Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo - TQTQliu/MVSGaussian
github.com



댓글