1. Introduction
Super-Resolution(SR)이란?
- SR은 저해상도 이미지(Low-Resolution, LR)로부터 고해상도 이미지(High-Resolution, HR)을 만드는 것을 의미한다
- Computer vision, Image Processing의 오랜 도전과제이다
실생활에서의 활용
- 의학 이미지 재건에 사용
- high definition (HD), ultra high definition (UHD) TV
- 모바일에서 더 큰 이미지, 비디오를 더 짧은 시간에 처리할 수 있게 됨 (큰 해상도의 이미지, 비디오 수요 증가)
SISR vs VSR
- Single Image Super Resolution (SISR)은 1개의 이미지를 처리하고 Video Super Resolution은 여러개의 연속적인 이미지/프레임을 처리한다
- 프레임 여러장을 super-resolve하여 연결시키면 VSR이 된다고 할 수 있지만 각각 처리할 경우 프레임간의 연관성이 떨어지게 되어 불필요한 artifacts를 만들 수 있다. 그렇게 때문에 VSR에서는 target frame하나를 처리할 때 이웃한 프레임들에서 정보를 잘 가져오는 것이 중요하다
- VSR에서는 YCbCr color space도 사용되는 경우가 많다
- VSR 알고리즘은 single frame을 처리한다는 점에서 SISR과 유사하나 (spatial information) / 이웃한 frames간 관계성을 이용해 motion consistency도 유지해야한다 (temporal information)
딥러닝을 이용한 VSR
- 딥러닝은 여러 분야에서 성공적으로 사용되었고 VSR에서도 그 효과가 입증되었다
- Convolutional Neural Network (CNN), Generative Adversarial Network (GAN), Recurrent Neural Network (RNN) 등 다양한 구조의 deep neural networks 기반 VSR methods가 연구되었다.
- 보통 학습시 LR video sequences와 HR video sequences를 네트워크의 입력으로 사용한다
- 네트워크의 출력으로는 LR이 SR된 HR video sequences이다
Pipeline of most VSR methods
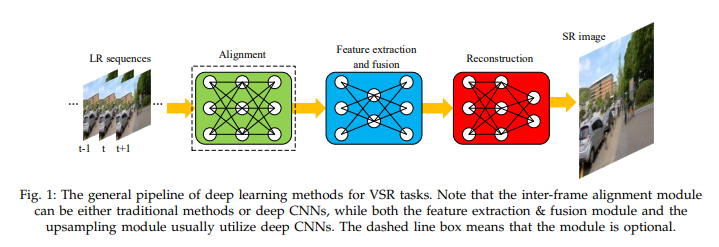
- alignment module -> feature extraction and fusion module -> reconstruction module
측정 지표
- peak signal-noise ratio (PSNR): measure the difference of pixels
- structural similarity index (SSIM): measure similarity of structures between two images
2. Methods with Alignment
- 추출한 모션 정보를 이용해서 neighboring frames를 target frame과 explicit하게 align한다
- 보통 motion estimation, compensation이나 deformable convolution을 사용한다
A. Motion Estimation and Compensation Methods

- Motion Estimation(ME)는 inter-motion information(프레임간 모션 정보)를 추출하는 것이다. 보통 ME는 두 이웃한 프레임간 temporal correlation과 variations를 통해 프레임간 motion을 계산하는 optical flow method를 통해 수행한다.
- Optical flow method는 2 frames(target, neighboring)를 inputs으로 가져와서 vector field를 계산한다
- Motion Compensation(MC)는 inter-frame motion information을 이용해 warping(image transform)을 해서 neighboring frame과 target frame을 align한다. Bilinear interpolation이나 spatial transformer network를 통해 얻을 수 있다.
- 단점: 빛의 급격한 변화나 큰 모션이 있을 경우 ME의 정확도를 보장 할 수 없다
B. Deformable Convolution Methods
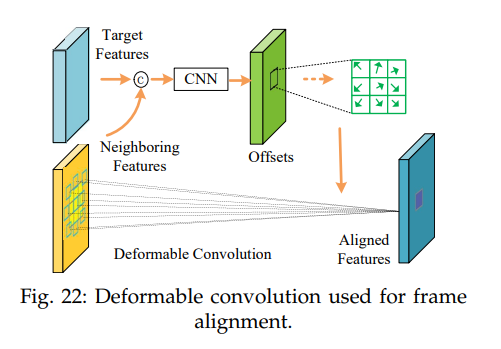
- 보통의 CNN에서는 레이어는 보통 기하학적으로 고정된 구조였으며 이는 기하학적 변환(geometric transformation)을 제한했다.
- Deformable convolution은 이 한계를 극복했다.
- Neighboring feature maps와 concat된 Target feature maps가 추가의 convolutional layer를 통해 offset을 얻기위해 투영된다
- Offset은 원래의 convolution kernel에 적용되어 deformable convolution kernel을 만들고 input feature maps에 적용g하어 output feature maps를 만든다
- 단점: Complexity가 높고 학습 수렴이 어렵다
3. Methods without Alignment
- Methods without alignment는 neighboring frames를 align하지 않는다
- 이 방법은 feature extraction을 위해 spatial하거나 spatio-temporal information을 이용한다
- 4개의 방법 중 2D Convolution을 이용하는 방법은 spatial한 방법이고 나머지 셋은 spatio-temporal한데 input videos에서 spatial, temporal informations를 둘 다 얻는다
A. 2D Convolution
- Input frames가 ME나 MC를 수행하지 않고 바로 2D convolutional network로 들어가서 spatially하게 feature extraction, fusion, super-resolution을 수행한다
B. 3D Convolution
- 3D convolution module은 spatio-temporal domain에서 연산을 수행한다 (kernel이 3D)
- 2D의 경우 sliding kernel을 통해 spatial information만 얻을 수 있다
- 3D convolution은 컴퓨팅 복잡도가 높아서 실시간으로 처리하기 어렵다
C. RCNN
- Recurrent Convolutional Neural Networks는 시퀀스 데이터를 처리할 때 temporal dependency를 잘 이용할 수 있다고 알려져왔다 ex) 자연어, 비디오, 오디오
- RCNN기반 방법은 더욱더 가벼운 구조로 long-term dependency를 얻을 수 있어서 비디오의 spatio-temporal한 정보를 모델링하기에 적합하다
- 그러나 gradient vanishing problem이 발생하는 등 학습이 쉽지 않고 입력 시퀀스가 너무 긴 경우 long-term dependency를 얻지 못할 수 있다
D. Non-Local
- Video classification에서 사용되던 non-local neural network에서 아이디어를 얻었다
- Convolution과 recurrent computations가 local area에 한정적이라는 한계를 극복했다
- Non-local operation은 각 위치에 해당하는 값(weight sum of all possible positions in the input feature maps)을 계산한다
- Receptive field를 global하게 늘릴 수 있기 때문에 spatio-temporal information을 효과적으로 얻을 수 있다
- 그러나 각 위치마다 계산을 해야하기 때문에 컴퓨팅 비용이 많이든다
6. Performance Comparisons
A. Datasets
Vimeo-90K
- 가장 널리 쓰이는 train dataset
- 실제 장면을 담았으며 가장 규모가 크다
- Train + Test: 91,701 (448 x 256)
- http://toflow.csail.mit.edu/
Vid4
- 가장 많이 쓰이는 test dataset
- 고주파 디테일이 많다
- Test: 4 (720 × 480 for Foliage and Walk, 720 × 576 for Calendar, and 704×576 for City)
REDS
- 큰 움직임을 가지고 있는 dataset
- Train + Test: 270 (1280 x 720)
- https://seungjunnah.github.io/Datasets/reds.html
7. Trends and Challenges
A. Lightweight Super-Resolution Models
- 딥러닝을 통한 VSR 모델은 파라미터 많아서 큰 용량을 차지하고 그 속도가 느린 경우가 많다
- 모바일 등의 적용을 위하여 가볍고 고성능의 모델을 만들어야 한다
B. Interpretability of Models
- 딥러닝은 input을 통한 output을 낼 수 있지만 무엇을 근거로 output을 냈는지 정확하게 알 수 없어 블랙박스 같다고 한다
- 그래서 사실 CNN이 어떻게 LR video sequences를 재건했는지 이론적으로 해석하기 어렵다
- 이를 연구하여 더 본질에 가까워 진다면 더 좋은 성능의 SR 알고리즘을 제시할 수 있을 것이다
C. Super-Resolution with Larger Scaling Factors
- 현재 많은 VSR은 x2, x3, x4배에 대해서만 다루는 경우가 많다
- 하지만 높은 해상도의 디스플레이가 출시되는 많큼 더 높은 scaling factors에 대한 SR이 연구되어야한다
- 크기를 더 많이 키우는 것이 더 어려운 문제이기 때문에 더욱 안정적이며 깊은 모델이 필요하다
D. Super-Resolution with Random Scaling Factors
- 실제 세상에 적용하기 위해서는 x2, x3, x4 이런식으로 scaling factors가 정해지기 보다 더 유연한 크기 변화에 대응할 수 있어야 한다
E. More Reasonable & Proprer Degradation Process of Videos
- 보통 LR 비디오는 HR을 interpolation을 사용해 바로 downsample하거나 가우시안 블러를 입힌후 downsample한다
- 실제 세계에서는 더 크고 복잡한 모션이 많으므로 degradation process도 이에 따라 처리할 필요가 있다
F. Unsupervised Super-Resolution Methods
- 대부분의 SOTA VSR methods는 supervised-learning이다
- 지도학습이기 때문에 수많은 LR-HR video frames 데이터가 필요하다
G. More Effective Scene Change Algorithms
- 대부분의 VSR methods는 scene change를 담은 비디오를 사용하지 않는다
- 그렇기 때문에 장면 전환이 있는 비디오는 비슷한 장면끼리 묶어 분류한 다음 따로따로 처리를 해야한다
- 이는 비용과 시간이 많이 든다
H. More Resonable Evaluation Criteria for Video Quality
- 현재 성능 측정은 PSNR과 SSIM을 통해 한다
- 하지만 이는 human perception을 반영하지 않는다. 즉 수치적으로는 좋은 비디오여도 사람이 보기에 좋지 않을 수 있다
I. More Effective Methods for Leveraging Information
- VSR에서 가장 중요한 문제는 프레임간의 정보를 어떻게 활용할까이다
- MEMC, 3D convolutions 등 다양한 방법이 제시되어 왔지만 여전히 단점들이 존재한다
이 글은 논문 "Video super resolution based on deep learning: A comprehensive survey"를 기반으로 작성했습니다
'기타 정보' 카테고리의 다른 글
| Optical Flow (0) | 2022.04.01 |
|---|---|
| 논문 scheme 뜻 (0) | 2022.03.06 |
| BasicSR Project 사용하기 (0) | 2022.02.12 |
| [OpenCV] OpenCV로 image resize를 하면 channel이 사라진다? (0) | 2022.02.10 |
| [Ubuntu] sh파일을 이용해 wget 여러번 하기 (1) | 2022.02.04 |



댓글