논문 요약
대부분의 고화질 비디오는 저장하는데 많은 자원이 소모되기에 낮은 해상도와 프레임 레이트로 저장된다. 하지만 최근 temporal interpolation과 spatial super-resolution을 통합한 Space-Time Video Super-Resolution (STVSR) 프레임워크를 통해 이 문제를 해결하고 있다. 그러나 대부분의 STVSR은 고정된 업샘플링 비율만 지원하기 때문에 제약이 있다. 본 논문은 이에 대한 대응책으로 Video Implicit Neural Representation (VideoINR)을 제안하고 이를 STVSR에 적용하였다. 학습된 INR은 비디오를 임의의 해상도, 프레임 레이트로 디코딩할 수 있다.
1. Paper Bibliography
논문 제목
- VideoINR: Learning video implicit neural representation for continuous space-time super-resolution
저자
- Chen, Zeyuan, et al.
출판 정보 / 학술대회 발표 정보
- Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022
2. Problems & Motivations
대부분의 비디오는 저장시 그 해상도와 프레임 레이트가 제한적일 수 밖에 없는데 이는 저장하는데 드는 비용이 매우 크기 때문이다. 이러한 비디오를 다시 사람들에게 보여줄 때 (예를 들어 TV로 다시 송출) 이러한 low resolution / low frame rate 비디오를 다시 high하게 제공할 필요가 있다.
이를 해결할 수 있는 방법 중 하나는 Space-Time Video Super-Resolution (STVSR)이다. 입력으로 들어온 비디오의 Spatial resolution과 frame rate를 동시에 키우는 것이다.
- Space
- spatial information
- Video Super-Resolution (VSR)
- 키우는 것: 해상도 - 디스플레이 표현력의 세밀함 정도
- Time
- temporal information
- Video Frame Interpolation (VFI)
- 키우는 것: 프레임 레이트 - 디스플레이 장치가 화면 하나의 데이터를 표시하는 속도
하지만 대부분의 STVSR은 고정된 비율(예: 2배, 4배 등)의 SR만 할 수 있었다는 한계점을 가지고 있다.
본 논문은 이와 다르게 임의의 크기의 SR이 가능한 VideoINR을 제안한다.
3. Method

VideoINR의 목표는 비디오에 대한 continuous representation을 찾는 것으로 이 representation은 임의의 space-time coordinate (xs,xt)를 RGB값으로 매핑해준다.
이는 multi-layer perceptrons (MLPs)로 파라미터화되며 다음과 같이 표현할 수 있다.
s=f(xs,xt)
- f: video representation
- xs: 2D spatial coordinate
- xt: temporal coordinate
- s: predicted RGB value
3.1 Continuous Spatial Representation
SpatialINR: predict the continuous feature of the query coordinate
- SpatialINR은 입력 공간 좌표를 continuous feature domain으로 만들어준다.
1) 쿼리 공간 좌표 xs 근처의 feature vector를 샘플링해 z∗를 얻는다.
2) 쿼리 공간 좌표 xs와 z∗의 공간 좌표 v∗와의 차이를 계산해 상대위치 정보를 구한다.
3) 1과 2를 concat한다.
3) 함수 fs에 넣어 쿼리 공간 좌표 xs에 대한 continuous feature를 만든다.
Fs(xs)=fs(z∗,xs−v∗)
- Fs: continuous feature domain defined by SpatialINR
- z∗: feature vector nearest to the query coordinate xs
- v∗: spatial coordinate of the feature vector z∗
- xs−v∗: relative position information between query coordinate and feature vector
3.2 Continuous Temporal Representation
TemporalINR: generate continuous motion flow of the query coordinate
- TemporalINR은 continuous temporal represetation을 위한 continuous motion flow field를 만든다
- 시공간 좌표 (xs,xt)와 연속된 두개의 입력이미지 I0,I1 를 통해 TemporalINR은 이를 continuous motion flow로 만들 수 있다.
M(xs,xt)=ft(xs,xt,I0,I1)
- (xs,xt): space-time coordinate
- I0,I1: two consecutive input frames
- M: continuous motion flow field
- ft: function for TemporalINR
- SpatialINR에서 이미 xs위치에서의 I0,I1에 대한 정보를 continuous feature형태로 얻었으므로 식을 다시 정의할 수 있다.
M(xs,xt)=ft(xt,Fs(xs))
- Fs(xs): feature domain defined by SpatialINR
3.3 Space-Time Continuous Representation
앞서 2개의 continuous representations를 얻었는데 이를 합쳐서 하나의 space-time continuous representation으로 만들어야 한다.
- space-time feature는 feature domain을 warp해서 얻을 수 있다.
- 쿼리 좌표 xs를 warp하면 x′s가 된다.
x′s=xs+M(xs,xt)
- x′: coordinate for continuous feature
- M(xs,xt): motion flow vector at (xs,xt)
- 새로 얻은 좌표 x′s를 통해 새로운 continuous 2D feature를 얻을 수 있다.
- 이는 공간 xs, 시간 xt에서의 정보를 모두 가지고 있다.
Fst(xs,xt)=Fx(x′s)=Fs(xs+M(xs,xt))
- (xs,xt): coordinate for continuous space-time representation
- Fst(xs,xt): continuous space-time feature
- 실제 구현에서는 양방향의 flows와 warped features를 만들어 concat했다.
3.4 Feature Decoding
마지막으로 features를 RGB 값으로 디코드해야한다.
- 이때 입력 정보를 풍부하게 하기 위해 각각 다른 스케일의 features를 만들고 이를 입력 프레임과 concat하여 디코딩에 사용한다.
4. Experiments
Datasets
Training
- Adobe240
- 비디오를 subset으로 나눔 (100, 16, 17 / train, val, test)
- 비디오를 시퀀스로 만들어서 학습. 각 시퀀스는 약 3000 프레임으로 구성
- 만든 시퀀스는 학습에서 high-resolution이 되고 Matlab의 imresize로 low-resolution을 만듬
Test
- Vid4, Adobe240, GoPro
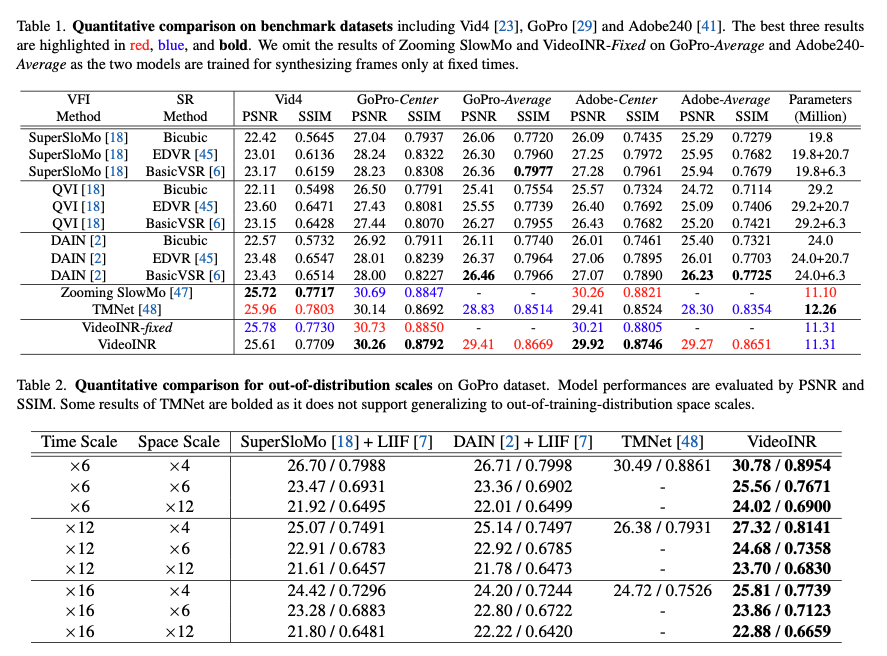
Results

Google Scholar Link
Google 학술 검색
Videos typically record the streaming and continuous visual data as discrete consecutive frames. Since the storage cost is expensive for videos of high fidelity, most of them are stored in a relatively low resolution and frame rate. Recent works of Space-T
scholar.google.co.kr
GitHub
https://github.com/Picsart-AI-Research/VideoINR-Continuous-Space-Time-Super-Resolution
GitHub - Picsart-AI-Research/VideoINR-Continuous-Space-Time-Super-Resolution: [CVPR 2022] VideoINR: Learning Video Implicit Neur
[CVPR 2022] VideoINR: Learning Video Implicit Neural Representation for Continuous Space-Time Super-Resolution - GitHub - Picsart-AI-Research/VideoINR-Continuous-Space-Time-Super-Resolution: [CVPR ...
github.com




댓글