1. Paper Bibliography
논문 제목
- Revisiting Temporal Alignment for Video Restoration
저자
- Zhou et al.
출판 정보 / 학술대회 발표 정보
- Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
년도
- 2022
2. Problems & Motivations
Existing alignment methods

Video restoration tasks에서 Long-range temporal alignment는 중요하지만 어려운 문제이다. 최근 long-range alignment를 여러 sub-alignment로 나누어 처리하여 점진적으로 발전시켜나가는 방법들이 제시되었다. 이러한 방법은 인근 프레임과의 의존성을 반영할 수 있었지만 에러가 계속 축적되는 문제를 가지고 있기도 하다.
i) independent alignment
- frame-to-frame alignment. central frame과 neighboring frame을 각각 alignment한다. 두 프레임간의 연관성만 고려하게 된다
ii) progressive alignment
- long-range alignment를 여러 sub-alignments로 나눠서 recurrent한 방법으로 처리하며 점진적으로 발전한다. 이러한 chain-rule-based propagation은 이전 단계에서 발생한 잘못된(misalignment) 정보가 계속 전달되어 에러가 축적된다.
iii) iterative alignment (논문의 방법)
- 점진적으로 sub-alignments를 공유하며 refine한다
Existing aggregation methods
여러 프레임들의 디테일은 유지하고 에러는 없애서 모으는 Aggregation역시 중요한 과정이다. 지금까지의 restoration systems는 sequential convolutions를 사용하여 바로 합치거나 spatial-temporal한 적응형 aggregation방법들을 사용한다(attention). 하지만 이는 모두 learned parameters에 기반하며 특정 도메인에 오버피팅될 위험성이 존재한다. 본 논문에서는 non-parametric re-weighting module을 제시한다.
3. Method
Overview
목표는 2N+1개의 low-quality images로부터 high-quality images를 만드는 것
Fig 3.과 같은 순서로 제시된다
1. Input frames는 strided convolution으로 downsample되어 들어가거나(deblurring, denoising) 그대로 들어간다(SR)
2. 그 다음 제시한 IAM을 통해 align 한다
3. adaptive re-weighting module을 통해 aligned된 features를 합친다
4. original input의 residual을 더해서 (SR이라면 upsample한것) 완성한다
Feature Extraction
먼저 RGB frame Ilqk를 고차원의 피처맵 Fk로 만들어야 한다. Deblurring, Denoising의 경우 먼저 2개의 convolution(stride=2)로 feature의 resolution을 downsample하며 SR은 크기를 유지한다. 그 다음 2개의 convolution을 통해 input의 pyramid representation을 얻는다. 마지막으로 하나의 convolution을 통해 합친다.
Temporal Alignment
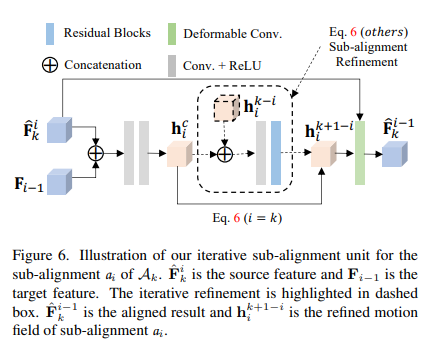
Iterative Alignment
1. 먼저 A1 alignment를 진행한다. A1은 sub-alignment a1로 구성되어 있다. a1은 aligned result \hat{F^1_0}와 estimated motion field h11를 만든다
2. 그 다음 A2 alignment를 진행한다. A2는 2개의 sub-alignment a2와 a1로 구성되어 있다. 이 때 a1는 A1에서 나온적이 있으므로 이전 결과인 h11를 가지고 initialize한 뒤 refine할 수 있다
3. A3은 3개의 sub-alignment a3, a2, a1로 구성되어 있으며 이 중 a2, a1는 최소 2번 최적화의 과정을 거쳤다고 할 수 있다
이러한 방식은 2가지 메리트가 있다
1. Sub-alignments는 반복적인 refinements를 통해 더 정확해진다
2. Sub-alignments는 이전에 align한 features뿐 만 아니라 pre-estimated motion field의 영향도 받는다
이 방법은 large motion에 큰 효과를 보인다
Iterative Alignment
위 알고리즘은 N(N+1)번 계산해야 한다. 그렇기 때문에 컴퓨팅 효율성을 고려해야 한다.
1. 이전 방법들은 여러 스케일을 다루기 위해 pyramid alignment scheme을 많이 사용했다. 하지만 본 논문에서는 이전에 feature extraction 단계에서 multi-scale fusion을 채택했기 때문에 single-scale alignment를 사용한다
2. compact한 residual blocks를 사용해 오버헤드를 줄였다
Adaptive Re-weighting
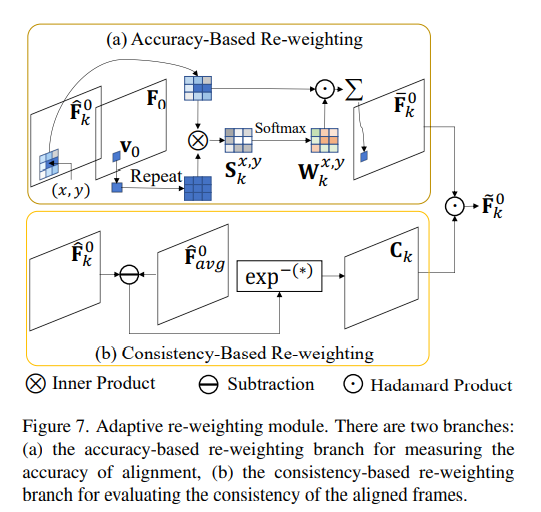
Align한 frame들을 잘 합치는 것이 중요하다. Aligned frames의 spatially-adaptive importance를 평가하는 non-parametric re-weighting module 제시
Accuracy-Based Re-weighting
aligned frame의 정확도를 측정한다. (x,y)주변 3ㅌ3 patch에 대한 cosine similarity를 계산한다
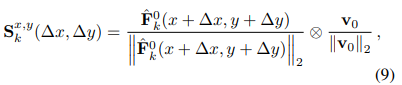
그 다음 softmax를 적용해 pixel-wise weights를 구한다
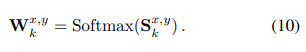
마지막으로 3x3 patch에 대해 feature vectors를 합치며 re-weighted result를 얻게 된다
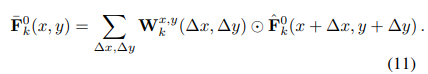
Consistency-Based Re-weighting
먼저 aligned neighboring frames의 평균을 계산한다. k번째 aligned frame과 다른 프레임들과의 consistency를 계산한다
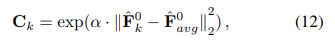
그 다음 accuracy-based re-weighted feature과 consistency map을 곱한다
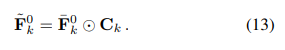
refined aligned feature는 reconstruction module로 들어가 high-quality결과물을 만든다
4. Experiments
Datasets
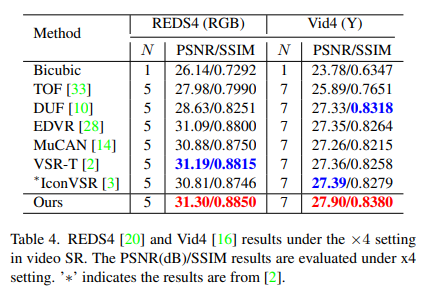
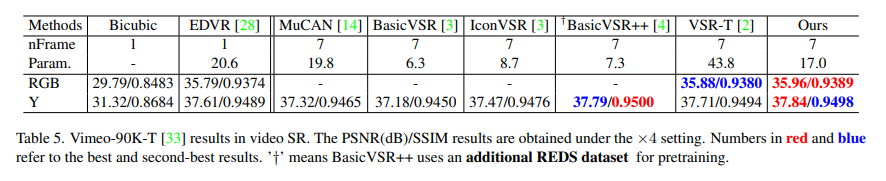
Video Super-Resolution
- Vimeo-90K: 64612 training, 7840 testing, 7-frame sequences with resolution 448 × 256
- REDS: 266 training, 4 testing, 100-frame sequences with resolution 1280 × 720
- Vid4: 4 testing video clips
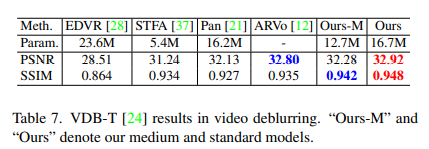
Video Deblurring
- Video deblurring dataset (VDB): 61 training and 10 testing video pairs. Each pair contains a blurry and sharp videos.
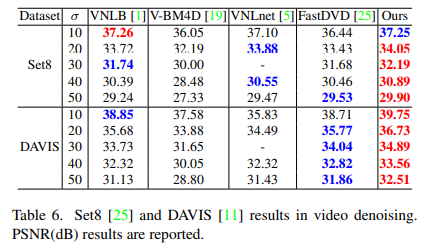
Video Denoising
- DAVIS: 87 training and 30 testing 540p videos
- Set8: for testing
Results
Video Super-Resolution
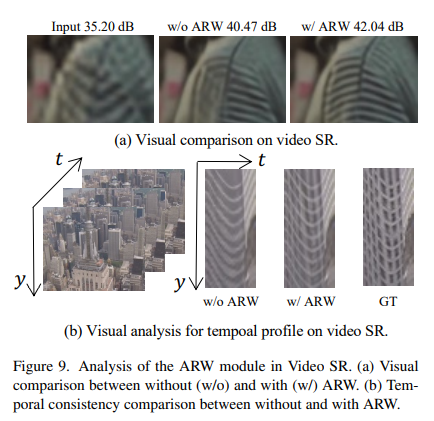

Video Deblurring

Video Denoising





댓글