1. Paper Bibliography
논문 제목
- EFENet: Reference-Based Video Super-Resolution with Enhanced Flow Estimation
저자
- Zhao et al.
출판 정보 / 학술대회 발표 정보
- CAAI International Conference on Artificial Intelligence. Springer, Cham, 2021.
년도
- 2021
2. Problems & Motivations
Reference-based Video Super Resolution (RefVSR)
"Reference-based Super-Resolution aims to recover high-resolution images by utilizing external reference images containing similar content to generate rich textures"
- papers with code
RefVSR은 HR reference 프레임을 활용하여 유사한 관점(similar viewpoint)의 카메라로 찍힌 LR 비디오 시퀀스를 SR하는 것이다.
다양한 방법들이 RefVSR을 위해 제시되었지만 videos를 위한 RefVSR은 아직 challenging하다. 2가지 이유가 있는데
1. the large parallax and resolution gap (e.g., 4×) makes it difficult to transfer details from HR frame to LR ones
- 큰 시차와 해상도차이 때문에 HR에 있는 디테일들을 LR에 전달해주기 어렵다
2. the potential large temporal gap between the HR and LR frames can lead to significant viewpoint drift among frames, therefore makes the regarding correspondence estimation error-prone
- HR과 LR사이의 시간적 갭이 크면 프레임간의 시점 오류(viewpoint drift)를 초래할 수 있으며 해당하는 지역에 에러가 발생한다
다른 resolution 사이의 프레임들을 잘 align하기 위해 flow estimator를 사용할 수 있다. 이를 통해 RefVSR을 여러개의 RefSR로 나눠서 볼 수 있지만 이는 중요한 시간적 정보를 없앤다.
여러 프레임들을 이용해 Flow estimation and motion compensation할 수 있으나 해상도 차이가 많이 날 경우 레퍼런스에서 얻는 정보가 줄어든다.
3. Method
RefVSR Strategies Analysis

EFENet의 방법은 Fig. 2. (d)이다.
- (a)와 다르게 긴 temporal한 정보를 얻을 수 있다
- (b), (c)와 다르게 reference 프레임과 각각의 LR 프레임들 간의 cross-scale flow를 예측하여 reference의 시작적인 정보를 최대한 활용한다
Network Structure
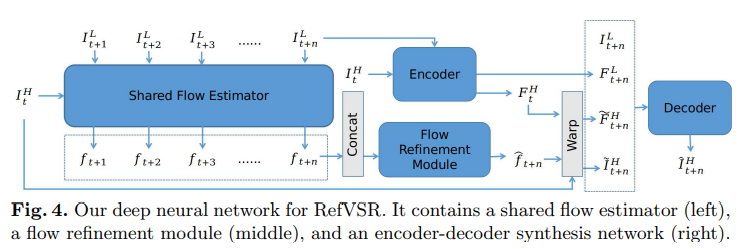
Shared Flow Estimator Module
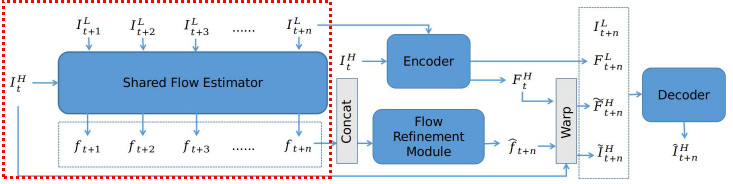
레퍼런스 $I^{H}_{t}$와 각 LR 프레임 사이의 correspondence를 estimate해서 n flow maps를 만든다

Flow Refinement Module

각 flow를 estimate하는 것은 temporal relationship을 무시한 채 진행되어 large motion이 있는 지역의 경우 sub-optimal한 결과를 만든다. 이를 해결하기 위해 flow refinement module을 제시한다
- flow refinement module: multiple time steps에서 만들어진 flow maps를 concatenation한 것을 input으로 얻어 time step $t+n$을 output으로 낸다
이전의 flows를 활용하여 시간적으로 멀리 있는 flow를 잘 refine하기 위해, 4 strided convolution과 de-convolution layers로 구성된 encoder-decoder를 사용한다. 이 구조는 2가지 장점이 있는데
1. encoder는 semantic, temporal information같은 high-level 정보를 잘 잡을 수 있다.
2. decoder는 de-convolution 과정에서 skip-connections를 사용하며 다른 scale의 피처들을 모아 flow를 enhance한다

Encoder-Decoder Synthesis Network
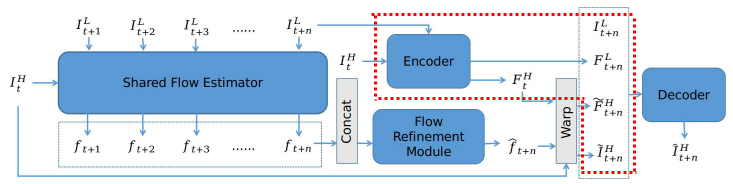
몇 번의 flow refinement 후 4 strided convolution과 de-convolution layers로 구성된 encoder-decoder를 사용하여 SR 결과를 만든다
구체적으로, 먼저 encoder $Net_{E}$로 $I^{H\uparrow }_{t+n, s}$과 $I^{H}_{t}$의 scale 1 feature map을 추출하고 scale을 줄여가며 $i-1 (for 1<i\leq 4)$ 반복적으로 convolve한다.

feature map을 인코딩 한 후 이전 시점의 refined flow와 warp한다

마지막으로 디코더를 통해 최종 결과를 만든다.
Feature maps ${F^{L}_{t+n,s}}$ 는 업샘플되고, warped reference features와 reaped reference는 concat되어 최종 결과를 만든다


Loss Function
학습을 위해 reconstruction loss와 warping loss의 combination을 사용한다
roconstruction loss:

flow에는 제약을 준다
for estimated flow:

for enhanced flow:
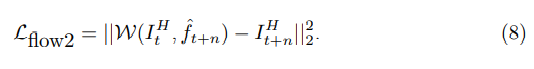
4. Experiments
Datasets
Train: Vimeo90K
Evaluate: Vimeo90K, MPII



Google Scholar Link
https://scholar.google.co.kr/scholar?hl=ko&as_sdt=0%2C5&q=EFENet&btnG=
Google 학술 검색
Z Zhao, H Yang, H Luo - Complex & Intelligent Systems, 2022 - Springer … Then, we develop an EFENet to obtain the edge information of in-focus objects from feature maps. Subsequently, the multi-scale contextual features and the edge information are …
scholar.google.co.kr
GitHub
https://github.com/IndigoPurple/EFENet
GitHub - IndigoPurple/EFENet: EFENet: Reference-based Video Super-Resolution with Enhanced Flow Estimation
EFENet: Reference-based Video Super-Resolution with Enhanced Flow Estimation - GitHub - IndigoPurple/EFENet: EFENet: Reference-based Video Super-Resolution with Enhanced Flow Estimation
github.com




댓글